The Context Architect: Why LLMs Need Better Context, Not Bigger Context Limits

The AI world is a little obsessed with size. Every few months, another lab announces a bigger, more cavernous context window - a million tokens, two million, soon probably ten. The dream they're selling is a simple one: just dump your entire codebase or all your data into the prompt, tell the AI to get to work, and lean back.
It's a tempting vision. It's also a trap, and it's training developers into genuinely bad habits.
While the big players in the AI ecosystem race to make incremental benchmark gains and push higher context limits, a quieter approach has been garnering real traction with engineers who've moved past the honeymoon phase: surgically managing what goes into the context window, rather than just filling it. The core idea is counter-intuitive. Giving a model more information often makes it perform worse while costing more resources. The practical sweet spot for high-quality, reliable output sits somewhere in the 20-60k token range, with 100k being roughly the ceiling where most models are still doing their best work. Not a million. That gap and the fact that these big players seldom mention how much of a model's context is actually usable in practice, is the whole point of this post. I think most can agree that LLMs don’t perform better with more context. They perform better with better context.
The 'Glorified Autocomplete' Self-Fulfilling Prophecy
There's a specific flavor of pearl-clutching worth addressing here, and a deep irony in how people talk about AI. Often, the loudest critics - the ones who dismiss LLMs as "glorified autocomplete" or complain about "AI-generated slop" - are some of the worst offenders when it comes to context management. Many have attempted to shoehorn in AI into their workflows and are frustrated or unimpressed by the results - but when peeling back the curtain, often we see that a few bad habits, like simply throwing their entire repo at the wall, writing a lazy one-sentence prompt, and just hoping the AI figures out the vibe of what they want, are probably the reason for poor performance or low quality.
It's truly a self-fulfilling prophecy. Treat a powerful reasoning engine like a garbage disposal, and you get garbage out. This reinforces the narrative that the tool is weak, when the weakness is in the methodology. Good prompt construction and surgical context management are not optional nice-to-haves - they're the difference between output you can actually use and output that's only fit to throw away. Research from Shi et al. at UCSD and Stanford backs this up directly: in their 2023 ICML study, they found that LLMs are easily derailed by irrelevant context in the prompt, even when the correct answer is clearly present elsewhere. The noise doesn't just fail to help - it actively degrades the model's ability to find the important signals in the context.
At a foundational level, an LLM's job is to predict the next best token based on the patterns in the context you provide. When that context is 95% noise, you're not giving the model more to work with; you are degrading its ability to find the info it should be focusing on. You wouldn't expect your IDE's autocomplete to write a complex function perfectly in one shot if you randomly pasted the entire text of Moby Dick above your cursor. So why do we, in practice, expect an LLM to sort out which context matters from a pile of everything?
Vibe coding with massive context windows doesn't test the limits of the AI. It just exposes a lack of engineering discipline and tool misuse.
The Hidden Costs of an Infinite Scroll
The problem with enormous context windows is that they look like a solution but often behave like a liability. Think of it like a woodworker who needs to make more cuts. Getting a bigger, longer saw seems like the obvious answer at face value, but that new saw might be too clumsy for fine detail work, too slow to get started, and exhausting to use all day. Often the solution isn't reaching for a bigger saw, but a better-organized workshop and the right saw for the job - a Japanese pull saw for precision, a rip saw for long cuts - each ready and waiting for its specific task where it's going to shine. The million-token window is that oversized saw in this example - it surely looks impressive, but it's probably not what a good craftsman would reach for in order to do their best or finest work.
When you dump a giant wall of text into the void, you're asking the model to find a needle in a continent-sized haystack. Benchmarks have shown LLMs have made real, measurable progress in long-context retrieval and Needle In the Haystack style tests - but there's no free lunch. Overfilling the context window has real costs:
-
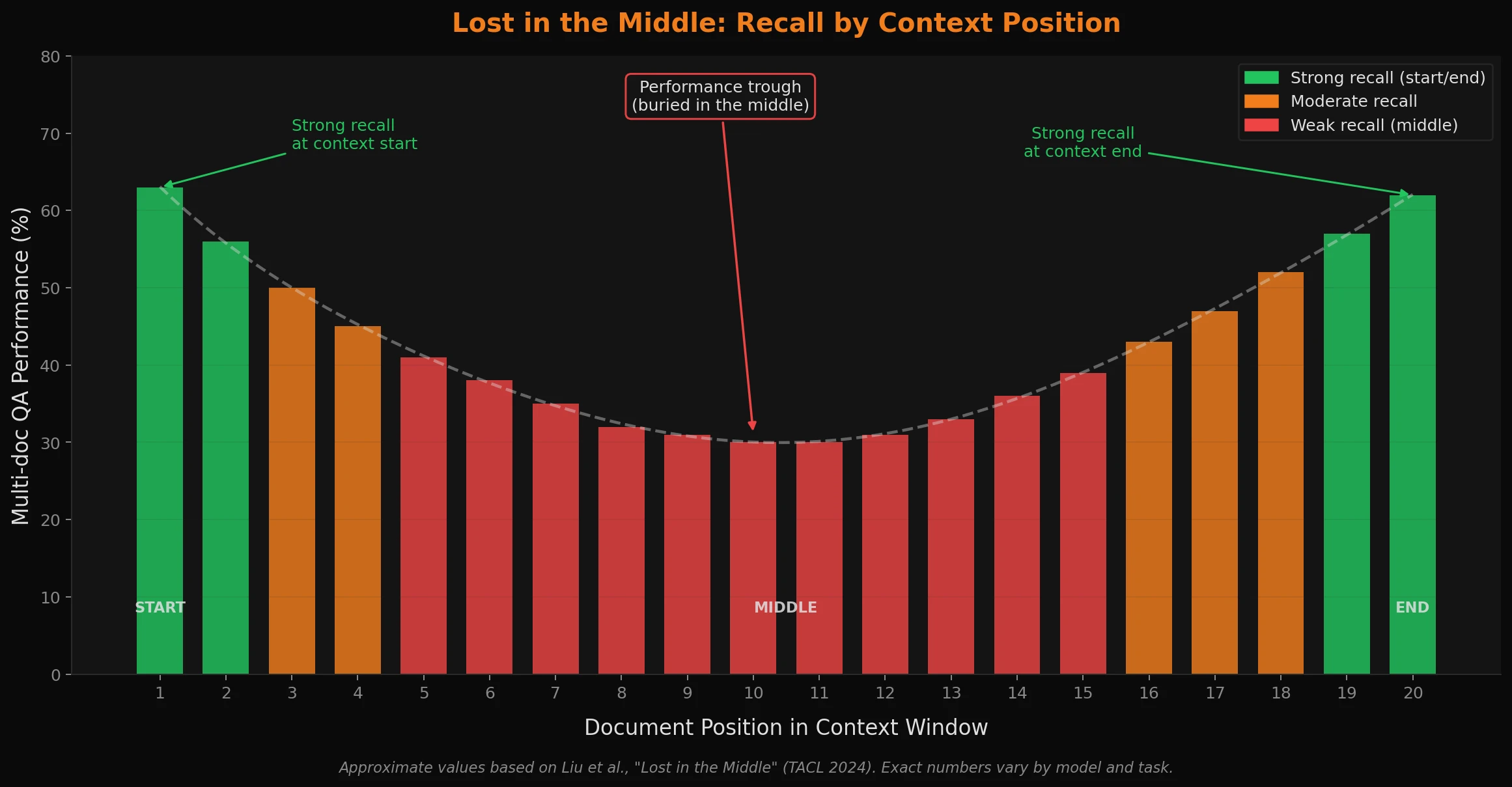
The 'Dumb Zone': Models tend to degrade as their context fills up. The mechanism has a name now - the "lost in the middle" problem - and the research backs it up: question answering performance drops sharply when relevant information is buried in the middle of a long context, even when the model is technically capable of retrieving it. Information at the start and end of a prompt is recalled far better than anything in the middle. Diluting the context with thousands of lines of irrelevant code or source info actively competes for the model's attention - and that's before you factor in any outdated, stale, or contradictory information from earlier in a long conversation poisoning the context going forward. Context poisoning is its own, separate and very real phenomenon with many implications in the practical application of building out AI and agent systems that function well with "real-world" data.
-
The Financial Drain: API calls are not free. Even in a homelab setup, there's always some cost - whether it's power, hardware wear, third-party API fees, and yes, even water usage (the true environmental footprint of inference is notoriously hard to pin down). A prompt with a million tokens of context can run dollars per turn. In a homelab, that same prompt might take 30 minutes to process a single turn. And if you're on a flat-fee subscription like Claude Pro or ChatGPT Plus and think this doesn't apply to you - bloated prompts hit rate limits dramatically faster. You're not paying per token, but you're still burning through your hourly or daily allowance (or weekly - I'm looking at you, Claude) at a fraction of the speed you otherwise would. If an agent makes a dozen tool calls in one step, you burn through your time or cost budget at a surprising rate, and most of that context is just noise competing for the model's attention that's actively making things worse. Cheaper, faster, and better quality are all achievable at once if you trim the fat.
-
The Molasses Effect: Large contexts are computationally expensive - for something like the Strix Halo machine that powers my homelab, that means dramatically slower response time (especially prompt prefill/processing!) and time to first token (TTFT). Waiting two to five minutes for an agent to think through and chew on a bloated prompt only to get a confused or off-target response that misses the mark is a total letdown and a workflow killer. Especially when another minute of adjusting the context or prompting could have fixed it, it kind of makes you feel guilty knowing the resource waste.
That million+ token window isn't a silver bullet - it's a blunt instrument and brutish approach, disguised as a solution to a problem not openly stated by frontier AI companies and labs.
From Context Dumper to Context Architect
The most effective AI developers I know are not just writing prompts. They're carefully considering and architecting the flow of information to the model. If there's anything the dozens of agent memory frameworks and RAG systems popping up everywhere seem to confirm, it's a shifting mindset in effective agentic development: from "how much can I stuff in?" to "what is the absolute minimum the AI needs to solve this specific problem?".
The Three-Tier Context Pipeline
This philosophy of "surgical context" is already being battle-tested by engineers who've discovered the pain points and noticed the quality degradation or expense, and have moved past the context-dumping phase on to greener pastures. Instead of one massive prompt or "context dump", they use a tiered pipeline that treats context as a valuable resource, progressively disclosing information as needed to avoid pre-seeding the model with conclusions or stale data.
The most effective workflows I've seen break down into a few layers I'm going to abstract here:
-
The Semantic Blueprint (Indexing): First, you use a fast, cost-efficient model to crawl your codebase and generate a high-level index. For every file, it produces a compact summary: what this file does, the public APIs it exposes, and how it connects to the rest of the system. This becomes a lightweight map of the whole project.
-
The Context Scout (Retrieval): When you have a task, a "Scout" agent takes your request and consults that Blueprint. Its only job is to be a discerning gatekeeper. Smaller models in the 7b range can fulfill this role surprisingly well, or can be orchestrated as a sub-agent and tool-call themselves. When properly implemented, it will comb through the source material and blueprint or index and identify the 5% of the codebase that actually matters for the current ticket/task and ignores the other 95% that would just constitute "noise". It's the difference between bringing the whole library to your desk, versus bringing the two or three books that actually have the relevant information.
-
The Master Craftsman (Execution): Only once the context is pruned and full of the high-signal and high quality info specifically needed to accomplish the task, do you call in the heavyweight model. Because it's only seeing a super-focused 30-80k tokens of content, its reasoning isn't diluted or filled with other leads it will try to chase and become distracted with. It doesn't have to guess which
utility.tsorroute.tsyou're talking about (I really do like Typescript, I promise). It has exactly the right info in front of it already, or it's one quick and simple tool call away to bring the info into context.

The result is a workflow that is purpose-built and likely much faster, significantly cheaper, and more accurate than the usual vibe coding tools and techniques that have permeated the internet over the last year or so. I think when we properly respect the model's attention, we're letting it function at its highest capability ceiling and performance level. High-quality input is the only reliable path to high-quality output - the old adage Garbage in, garbage out still rings as true as ever!
A Practical Blueprint: My TASK_CONTEXT System
I promise this isn't just me pontificating about something purely theoretical. It really is at the core of how I manage pretty much all of my development projects. Instead of relying on chat history or a memory framework or a fancy vector database, I maintain a simple, structured markdown file in each project's root which I call TASK_CONTEXT.md. It's the shared scratchpad between my agent(s) and me.
It's the AI's mission control. The first thing it reads, the last thing it updates. Dense, scannable, and high-signal. Here's what it looks like:
# TASK CONTEXT
## Current Sprint Goal
> One-sentence description of the high-level objective.
## Recent Changes
- path/to/file.ext - MODIFIED - Brief note on what changed and why.
## Key Architectural Decisions
- Critical, non-obvious facts the AI must not forget.
- e.g., "Field MUST be named `map_group` for lookup to fire."
- e.g., "Direct EWRAM addresses fail here; use `ptr:` dereferencing."
## Blockers / Open Questions
- What I'm currently stuck on or need to verify.
## Next Steps
1. First, do this.
2. Then, do this.
## Quick Pick-Up (for AI & partner)
- **File focus:** `<comma-separated list>`
- **Remember:** `<the most critical rule for this specific task>`
Every section earns its place:
- Sprint Goal: Orients the AI to the "why" behind the immediate task.
- Recent Changes and Key Decisions: The short-term memory and the tribal knowledge. This is where I codify tricky discoveries and hard-won lessons that would otherwise get lost in a long chat history. It prevents the AI from making the same mistake twice.
- Next Steps: The plan. Keeps the agent on-rails and focused on the immediate milestone.
- Quick Pick-Up: The ultimate distillation. If the agent had to restart with only 10 seconds of prep, this section is enough to get it back on track.
The file stays useful only if you actively prune it. As Recent Changes accumulates entries, the older discoveries get distilled into Key Architectural Decisions - the hard-won rules that permanently shape how you approach the project. Everything else gets cut. A TASK_CONTEXT that grows without pruning eventually becomes the exact kind of noise it's supposed to prevent.
Something like this simple file is often more powerful than a million tokens of context because it's curated, structured, and intentional. It's a living document that encodes the intent, constraints, and current plan - the architectural blueprint for the AI's attention.
The 20-60k Sweet Spot (and Why 100k Is the Ceiling)
That 20-60k range isn't a hard rule - it's a practical observation, and one that's increasingly backed by benchmarks. It represents the zone where context is rich enough to provide full situational awareness without crossing into territory where attention starts getting diluted and costs start compounding for diminishing returns.
The "lost in the middle" effect doesn't kick in at some theoretical maximum. It starts eating into model performance well before you hit 100k tokens, and the degree depends on task type and how well-organized your context is. Below roughly 100k, with well-structured context, most current models still perform reliably. Above it, you're on a slope, and you're paying more - in cost, latency, and quality - for progressively worse returns.
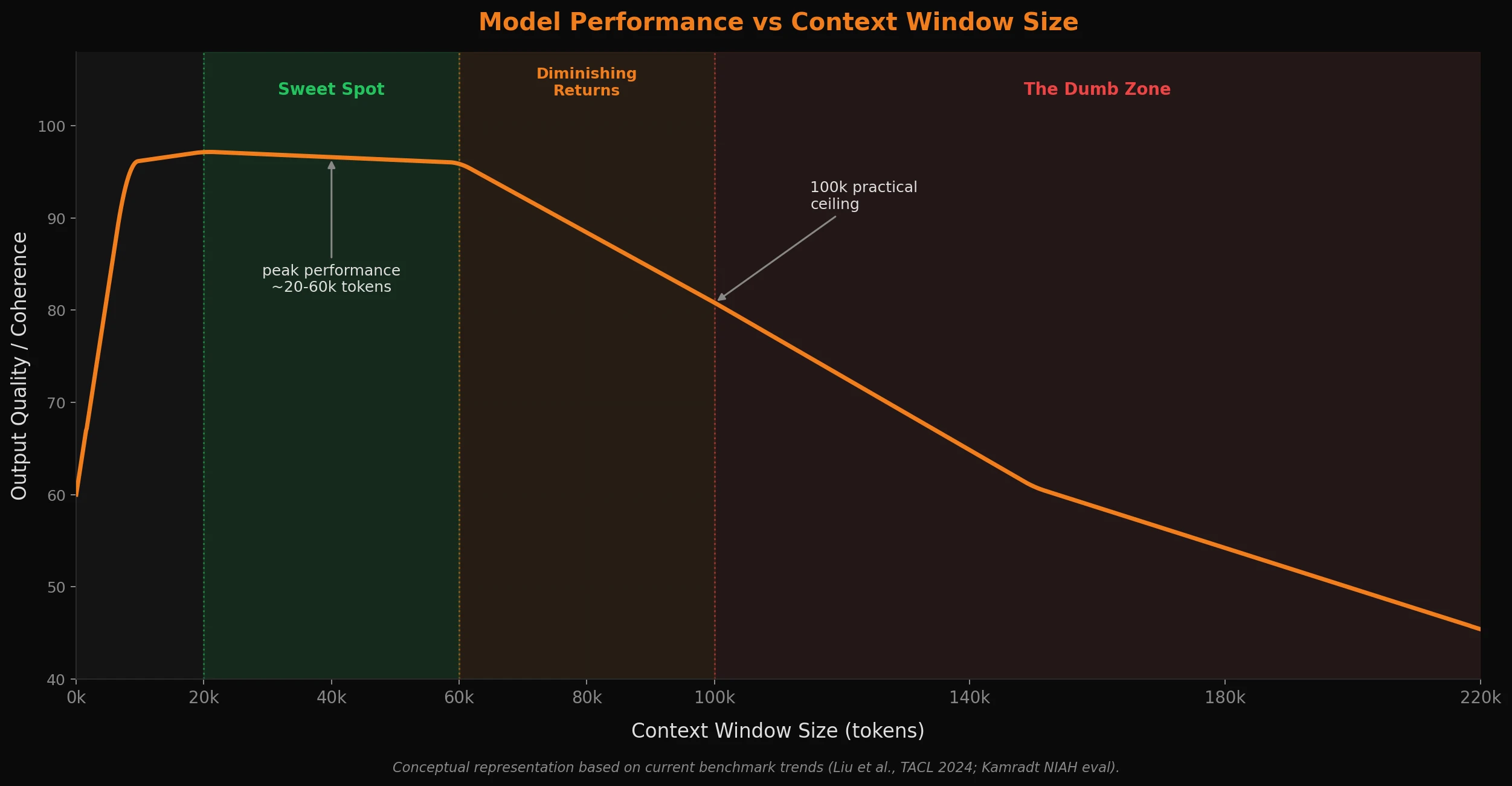
I was there when 32k token context limits felt enormous and luxurious, even. Times have changed, but I think it's easy to forget where we came from in this crazy fast moving industry, and that tight-context constraints probably forced better habits out of us as developers, at least in some ways regarding context management. The discipline of treating context as a scarce resource is worth keeping, even now that it's technically abundant. The economics and the quality data both point in the same direction.
This approach to context management echoes the Research-Plan-Implement (RPI) workflow that seems to be an emerging pattern many developers are moving towards:
- Research (Blueprint + Scout): The agent explores the codebase, reads files, gathers information via the index. Context is broad but shallow - this is what the Blueprint and Scout stages are doing.
- Plan: The agent synthesizes its research into a detailed step-by-step plan. Context shifts to strategy and intent. This is often the right point to clear the context entirely.
- Implement (Craftsman): The agent executes the plan, one step at a time. Context becomes narrow and deep, focused only on the files and functions needed for the current step. This is the Craftsman operating at full capacity.
Each phase has its own purpose-built context. You don't drag the full research history into the implementation phase. You give the agent what it needs, when it needs it, and pretty much only what it needs.
The Craftsman's Edge
The future of building software isn't about replacing engineers with all-knowing AI oracles. It's about a more useful collaboration, with the developer's role shifting - from being primarily a coder to being a systems thinker, a problem decomposer, and an architect of both infrastructure and context.
We don't have to sacrifice the pride in our craft or the appreciation for a well-architected system in order to work effectively with AI. Historically, what's made developers valuable is the ability to adapt and master our tools. Directing this technology with precision is just the next skill in that lineage.
Architect your prompts and context windows with the same meticulous rigor you apply to your codebases. The results will speak for themselves.